|
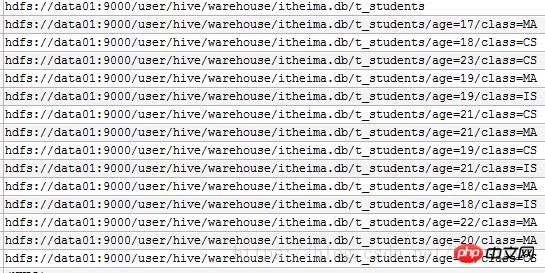
导读网页的本质就是超级文本标记语言,通过结合使用其他的Web技术(如:脚本语言、公共网关接口、组件等),可以创造出功能强大的网页。因而,超级文本标记语言是万维网(Web)编程的基础,也就是说万维网是建立... 网页的本质就是超级文本标记语言,通过结合使用其他的Web技术(如:脚本语言、公共网关接口、组件等),可以创造出功能强大的网页。因而,超级文本标记语言是万维网(Web)编程的基础,也就是说万维网是建立在超文本基础之上的。超级文本标记语言之所以称为超文本标记语言,是因为文本中包含了所谓“超级链接”点。 本篇文章给大家带来的内容是关于避免HIVE分区入门踩坑必学的五大知识,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。HIVE-分区入门踩坑hive 分区概念在先: Demo步骤: 1.创建一个学生分区表 95001,李勇,男,20,CS --分区表创建create table t_students(id int,name string,sex string) partitioned by (age int,class string)row format delimited fields terminated by ',' ; 创建后看一下成功没有 hive> set hive.cli.print.header=true;hive> select * from t_students;OK t_students.id t_students.name t_students.sex t_students.age t_students.class 2.添加内容 --静态分区load data local inpath '/root/logs/students.txt' into table t_students partition (age=19,class='MA'); (2)insert --动态分区set hive.exec.dynamic.partition=true;set hive.exec.dynamic.partition.mode=nonstrict;insert overwrite table t_students partition (age,class) select * from t_student; 执行之后查看元数据SDS表 , 可以看到所有映射信息 --使用同样的数据,再次追加insert一次数据 hive> insert into table t_students partition (age,class) select * from t_student; 再次追加一次数据后,元数据SDS表信息不变,每条分区路径下的文件变为两份 hive 分桶分桶是相对分区进行更细粒度的划分。分桶将整个数据内容安装某列属性值得hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。 以上就是避免HIVE分区入门踩坑必学的五大知识的详细内容,更多请关注php中文网其它相关文章! 网站建设是一个广义的术语,涵盖了许多不同的技能和学科中所使用的生产和维护的网站。 |
温馨提示:喜欢本站的话,请收藏一下本站!
本站发布的Win7纯净版系统、Win10纯净版和XP纯净版系统仅为个人学习测试使用,请在下载后24小时内删除,不得用于任何商业用途,否则后果自负,请支持购买微软正版软件!
本站所有资源全部来自于网络资源,如侵犯到您的权益,请及时通知我们(peng896066052@126.com),我们会及时处理.
Copyright © 2018-2020 雨林木风下载站